Does your application scale with your business?
In today's world of open-source (read "free") frameworks and increasingly cheap hardware, the limit of applications is being tested more than ever before. An idea is brewed over latte and chai in the neighborhood coffee-shop, is somehow translated into boxes-and-arrows on a whiteboard, and six months later, is receiving over a million hits. So, as it turns out, the idea was really good and is on its way, as was intended. The problem is most enterprise web applications are not ready to scale and handle the requirements of large volumes, high availability and performance without some refactoring (read "high cost" and "bug-prone") or using some off-the-shelf solution or both. It is a real-world challenge for IT professionals to deliver on the promise of always-on, highly performing web applications. Also, to combat this challenge, it is widely accepted that scaling out an application (moving it from one to many physical machines) is a lot more cost affective and flexible than scaling up (increasing the capacity of the single machine).
Let's look at this problem within the context of a web application, which is deployed on multiple machines (scale-out).
In typical non-static web applications, the persistent data is stored in a database and the transient (lasting only a short time; existing briefly; temporary) data is stored in a session. A session is the duration for which the user is actively interacting with the web application. Since this data only needs to live while the user is interacting with the application, it is transient in nature. Now, persistent data can be accessed by multiple application instances from multiple physical locations, as the application communicates with the database through a network connection. This is not true for transient data. The transient session data resides on the local memory and can only be accessed by the local single application instance. Needless to say, if one of these instances goes down due to any reason, all the sessions on that instance would be lost. Hence the need for a clustering solution that will make this transient session information available to multiple nodes in a cluster, without compromising the integrity of the data.
A good clustering solution should offer the following:
1. Simple. It should be as simple as possible, but not simpler.
2. Fast. It should be high-performing and hence linearly scalable (within the constraints of the network speed and bandwidth). In other words, moving an application from one to many nodes should not decrease the overall system performance.
3. Reliable. It should be easy to maintain and dependable.
In this article, we will highlight a couple of solutions available today for scaling web applications deployed on the Apache Tomcat Servlet Container (Tomcat) and compare these solutions based on simplicity, performance and reliability.
Tomcat:
Tomcat is one of the most widely used Servlet Containers available today and is one of the official Reference Implementations for the Java Servlet and JavaServer Pages technologies. It allows web applications to store transient data through the HttpSession interface, which it internally stores in a HashMap. It creates a unique session for each user, and allows the application to set and get attributes to and from the session. The basic requirement of clustering any web application with Tomcat is to distribute these sessions across multiple nodes in a cluster, for which we will look at the following options:
1. The Tomcat Sessions Clustering solution shipped with Apache Tomcat of the Apache Software Foundation.
2. Terracotta Sessions, which is one of the many clustering solutions offered by Terracotta, Inc.
Before we delve into the comparison, it is important to look at the underlying architecture of the two solutions and their approach towards clustering.
Tomcat Clustering:
Tomcat's homegrown clustering solution is built on a peer-to-peer architecture and replicates the session at the application level. In this approach, whenever the session changes, the entire session is serialized on disk and is sent to every other node in the cluster. The developer must be careful to call setAttribute() on the session to make sure the important changes are propagated across the cluster. How often and where the developer calls setAttribute() can be a little tricky (if you forget to call it, you won't know it's broken until a failover happens; if you call it too often, you have potential production performance-degradation on your hands that might take days or weeks to fix, provided you can find the root-cause).
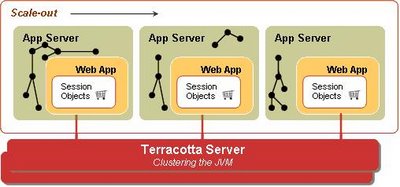
Terracotta Sessions:
Terracotta Sessions uses Terracotta's Distributed Shared Objects (DSO) technology which is built on a hub-and-spoke architecture. This technology takes a radical approach of clustering at the JVM level, which has some powerful advantages. The solution drills down at the byte level and is able to figure out at run time the bytes that have changed, and only propagates those bytes. The hub-and-spoke architecture eradicates the need to send the changed bytes to every other node in the cluster. This also means that the session is clustered without writing any additional code (yes, no serialization required), which makes it very inviting with an operations perspective. Very cool.
 Part 2 ->
Part 2 ->












4 comments:
Can anyone recommend the well-priced Endpoint Security system for a small IT service company like mine? Does anyone use Kaseya.com or GFI.com? How do they compare to these guys I found recently: N-able N-central change management
? What is your best take in cost vs performance among those three? I need a good advice please... Thanks in advance!
I found a great deal of helpful information above!
So good information I enjoy so much because you make me learn more about this important topic
Thank you for the efforts you been putting on making your site such an interesting and informative place to browse through.
Post a Comment