Scaling out a java application traditionally has not been easy. There are a number of technologies that allow you to distribute data across multiple JVMs, but most of them are cumbersome, high maintenance and do not scale linearly. Let's discuss the pain points involved in using three different approaches namely EJBs, JMS and POJOs.
I am going to start this article by outlining my experience as a server lead for a major services company for more than 3 years, focusing mainly on the major pain points we faced in an effort to cluster our application in a cost effective manner. The experience was a hair-losing and maddeningly frustrating one.
When I started work, it was very obvious to me that there needed to be an effort to redesign the existing architecture of the system. It was a typical consumer facing application serving web and mobile clients. The entire application was written in Java (
JSE and
JEE) in a typical
3-tier architecture topology. The application was deployed on 2 application server nodes. All
transient and
persistent data was pushed into the Database to address high availability. As it turned out, as the user-base grew, the database was the major bottleneck towards
RAS and performance. We had a couple of options: pay a major database vendor an astronomical sum to buy their clustering solution, or redesign the architecture to be a high-performing
RAS system. Choosing the first option was tempting, but it just meant we were pushing the real shortcomings of our architecture "under the carpet", over and above having to spend an as

t
rnomical sum. We chose the latter.
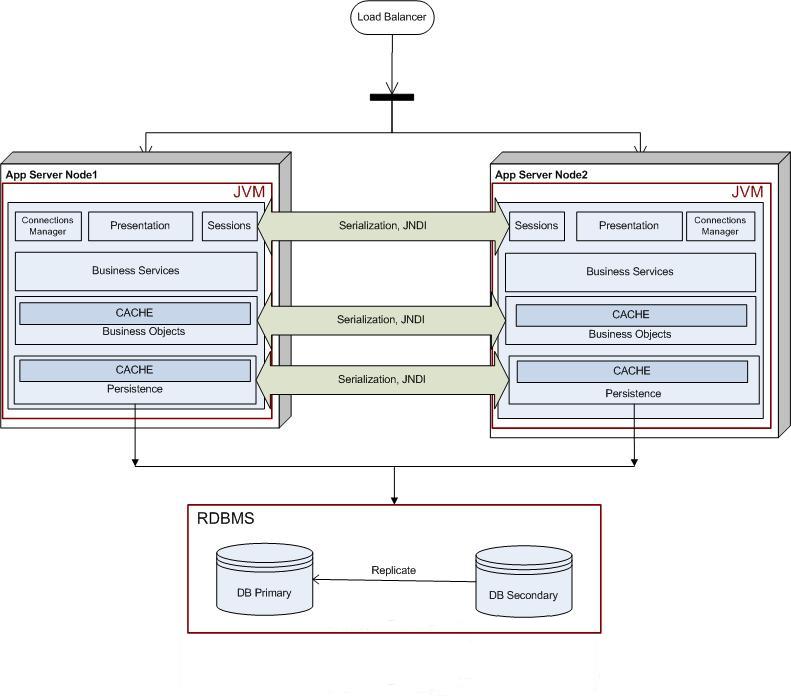
In the next evolution of the application, we made a clear demarcation between the transient and persistent data, and used the database to store only the "
System of Record" information. To distribute all the transient information (sessions, caches etc.), we took the EJB+JNDI route (this was in 2001-2002).
This is what our deployment looked like. Some of the known shortcomings of EJBs are that they are too heavy-weight and make you rely on a heavy weight container. EJB3 has somewhat changed that. In terms of clustering, we found the major pain point to be the JNDI discovery.
If you implement an independent JNDI tree for each node in the cluster, the failover is developer's responsibility. This is beacause the remote proxies retrieved through a JNDI call are pinned to the local server only. If a method call to an EJB fails, the developer has to write extra code to connect to a dispatcher service, obtain another active server address, and make another call. This means extra latency.
If you have a central JNDI tree, retrieving a reference to an EJB is a two step process: first look up a home object (Interoperable Object Reference or IOR) from a name server and second pick the first server location from the several pointed by the IOR to get the home and the remote. If the first call fails, the stub needs to fetch another home or remote from the next server in the IOR and so on. This means that the name servers become a single point of failure. Also, adding another name server means every node in the cluster needs to bind its objects to this new server.
As a result, over the next three years, we moved on from EJBs and adopted
the
Spring Framework in our technology stack, along with a bunch of open source frameworks:
Lucene for indexing our search,
Hibernate as our ORM layer, role based security,
Quartz for scheduling. We also dumped our proprietary Application Server for an open source counterpart. We wrote a
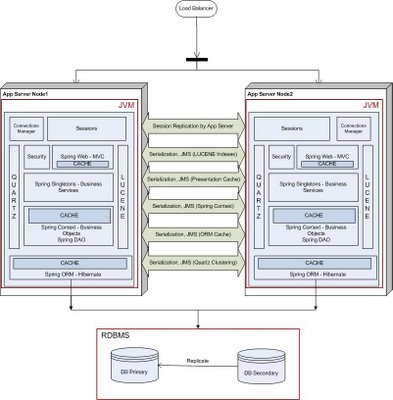
JMS layer to keep the various blocks in the technology stack coherent across the cluster. To distribute the user session, we relied upon our application server's session replication capabilities.
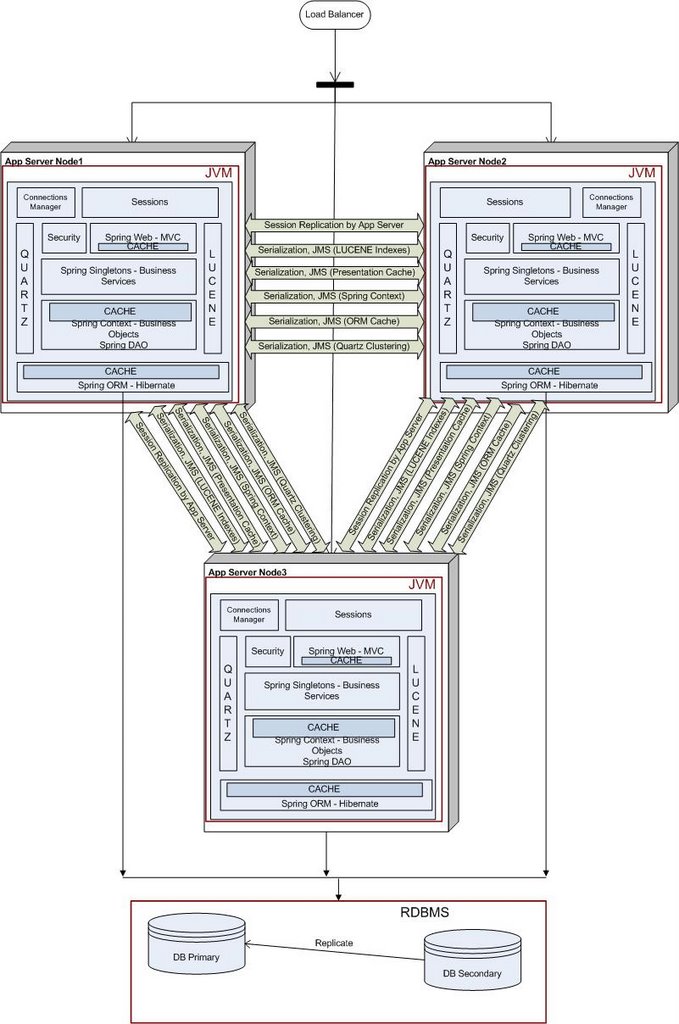
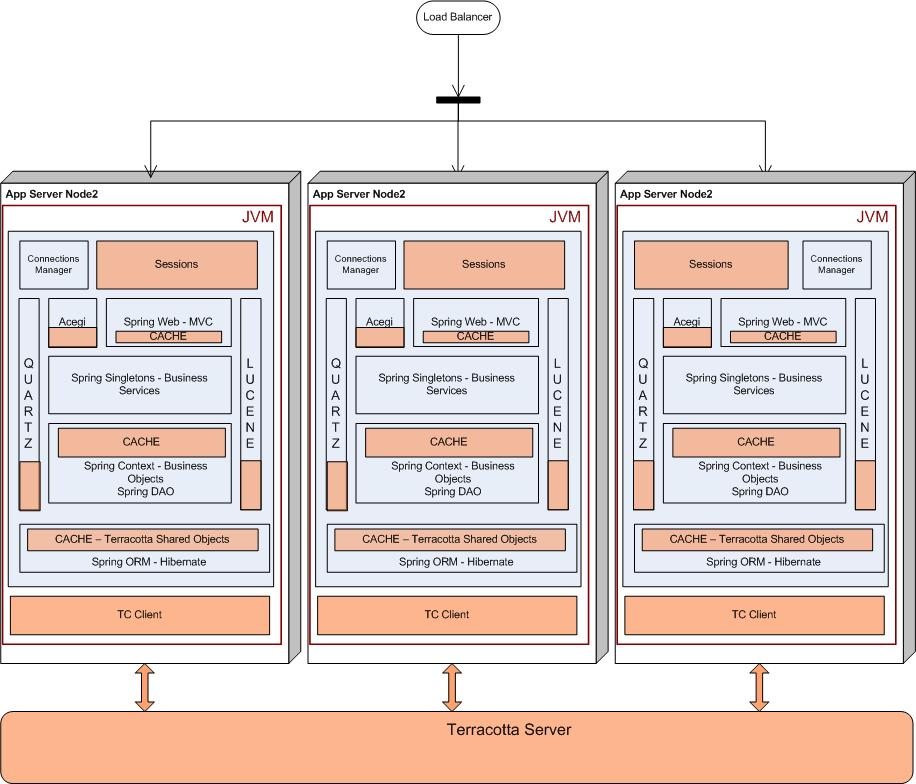
This is what our deployment looked like in mid 2006.
As you can see, our architecture had evolved into a stack of open source frameworks, with many different moving parts. The distribution of shared data happened through the JMS layer. The main pain points here were the overheads of serialization and maintaining the JMS layer.
The application developer had to make sure that all of these blocks were coherent across the cluster. The developer had to define points at which changes to objects were shipped across to the other node in the cluster. Getting this right was a delicate balancing act, as shipping these changes entailed serializing the relative object graph on the local disk and shipping the entire object graph across the wire. If you do this too often, the performance of the entire system will suffer, while if you do this too seldom, the business will be affected.
This turned out to be quite a maintenance overhead. Dev cycles were taking longer and longer as we were spending a lot of time maintaining the JMS layer. Adding any feature meant we had to make sure that the cluster coherency wasn't broken.
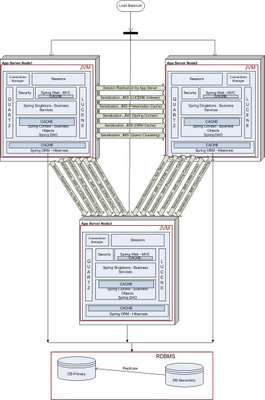
Then came the time when we needed add another node into our cluster to handle increased user traffic.
This is what our deployment looked like. With each additional node in the cluster, we had to tweak how often the changes were shipped across the network in order to get optimum throughtput and latency and so as not to saturate the network. The application server session replication had its own problems with regards to performance and maintenance.
The irony is that every block in our technology stack was written in pure JAVA as POJOs, and yet there was a significant overhead to distribute and maintain the state of these POJOs across multiple JVMs. One can argue that we could have taken the route of clustering our database layer. I will still argue that doing so would have pushed the problems in our architecture under the DB abstraction, which would have surfaced later
as our
usage grew.
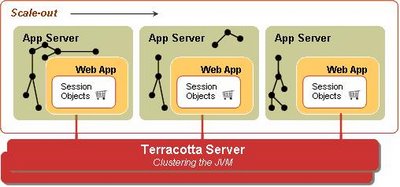
I have now been working at Terracotta for a while and have a new perspective from which to
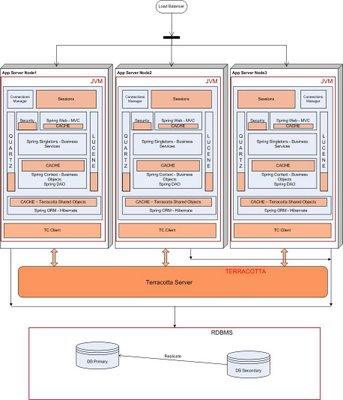
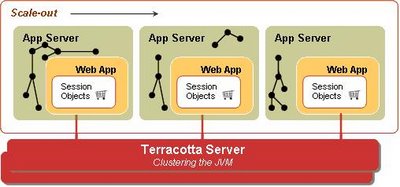
look at the above problem. Terracotta offers a clustering solution at the JVM level and becomes a single infrastructure level solution for your entire technology stack. If we had access to Terracotta,
this is what our deployment would have looked like. You would still use the database to store the "System of Record" information, but only that.
Terracotta allows you to write your apps as plain POJOs, and declaratively distributes these POJOs across the cluster. All you have to do is pick and choose what needs to be shared in your technology stack and make such declarations in the Terracotta XML configuration file. You just have to declare the top level object (e.g. a HashMap instance), and Terracotta figures out at runtime the entire object graph held within the top level shared object. Terracotta maintains the cluter-wide
object identity at runtime. This means obj1 == obj2 will not break across the cluster. All you need to do in the app is get() and mutate, without an explicit put(). Terracotta guarantees that the cluster state is always coherent and lets you spend your time writing business logic.
Since Terracotta shares the state of POJOs at the JVM level, it is able to figure out what has changed at the byte level at runtime, and only ship the deltas across to other nodes, only when needed. The main drawback of database/filesystem session persistence centers around limited scalability when storing large or numerous objects in the HttpSession. Every time a user adds an object to the HttpSession, all of the objects in the session are serialized and written to a database or shared filesystem. Most application servers that utilize database session persistence advocate minimal use of the HttpSession to store objects, but this limits your Web application's architecture and design, especially if you are using the HttpSession to store cached user data. With Terracotta, you can store as much data in the HttpSession as is required by your app, as Terracotta will only ship across the object-level fine grained changes, not all the objects in the HttpSession. Also, Terracotta will do this only when this shared object in the HttpSession is accessed on another node (on demand), as Terracotta maintains the
Object Identity across the cluster.
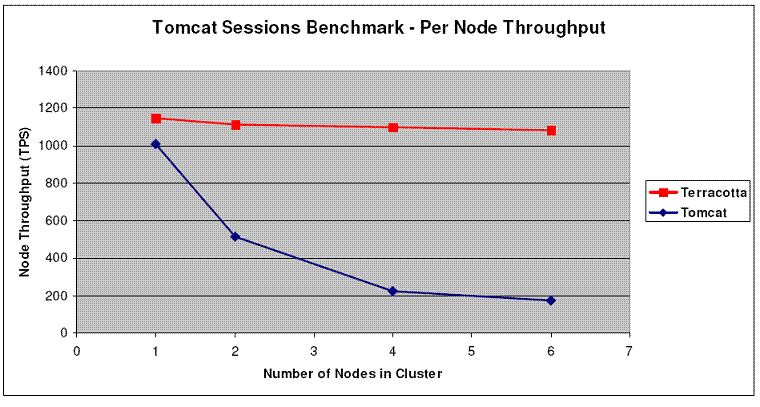
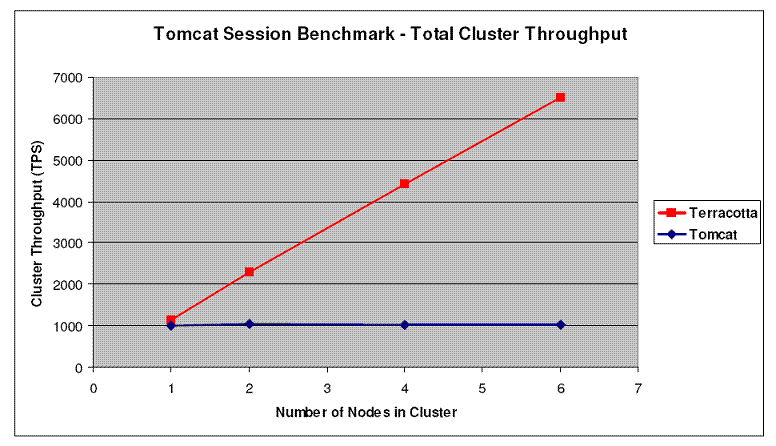
Here are some benchmarking results.
When I looked closely at the Terracotta clustering technology after I started working here, I couldn't help but look back at those 3+ years I spent with my team trying to tackle everyday problems associated with clustering a Java application.
All the pain points I mentioned above are turned into gain points by Terracotta: no
serialization, cluster-wide
object identity, fine grained sharing of data and high performance.
Bottom Line: Terracotta is the only technology available today that lets you distribute POJOs as-is. Introducing Terracotta in your technology stack lets you spend your development resources on building your business application.
Links:
Terracotta web site.Download Terracotta.
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}