I am going to start this article by outlining my experience as a server lead for a major services company for more than 3 years, focusing mainly on the major pain points we faced in an effort to cluster our application in a cost effective manner. The experience was a hair-losing and maddeningly frustrating one.
When I started work, it was very obvious to me that there needed to be an effort to redesign the existing architecture of the system. It was a typical consumer facing application serving web and mobile clients. The entire application was written in Java (JSE and JEE) in a typical 3-tier architecture topology. The application was deployed on 2 application server nodes. All transient and persistent data was pushed into the Database to address high availability. As it turned out, as the user-base grew, the database was the major bottleneck towards RAS and performance. We had a couple of options: pay a major database vendor an astronomical sum to buy their clustering solution, or redesign the architecture to be a high-performing RAS system. Choosing the first option was tempting, but it just meant we were pushing the real shortcomings of our architecture "under the carpet", over and above having to spend an as
 trnomical sum. We chose the latter.
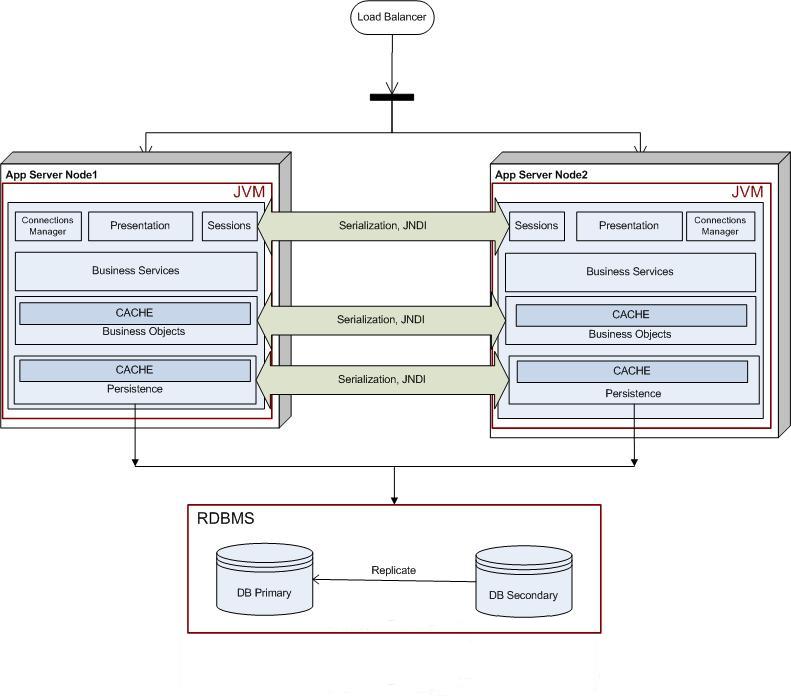
trnomical sum. We chose the latter.In the next evolution of the application, we made a clear demarcation between the transient and persistent data, and used the database to store only the "System of Record" information. To distribute all the transient information (sessions, caches etc.), we took the EJB+JNDI route (this was in 2001-2002). This is what our deployment looked like. Some of the known shortcomings of EJBs are that they are too heavy-weight and make you rely on a heavy weight container. EJB3 has somewhat changed that. In terms of clustering, we found the major pain point to be the JNDI discovery.
If you implement an independent JNDI tree for each node in the cluster, the failover is developer's responsibility. This is beacause the remote proxies retrieved through a JNDI call are pinned to the local server only. If a method call to an EJB fails, the developer has to write extra code to connect to a dispatcher service, obtain another active server address, and make another call. This means extra latency.
If you have a central JNDI tree, retrieving a reference to an EJB is a two step process: first look up a home object (Interoperable Object Reference or IOR) from a name server and second pick the first server location from the several pointed by the IOR to get the home and the remote. If the first call fails, the stub needs to fetch another home or remote from the next server in the IOR and so on. This means that the name servers become a single point of failure. Also, adding another name server means every node in the cluster needs to bind its objects to this new server.
As a result, over the next three years, we moved on from EJBs and adopted
 the Spring Framework in our technology stack, along with a bunch of open source frameworks: Lucene for indexing our search, Hibernate as our ORM layer, role based security, Quartz for scheduling. We also dumped our proprietary Application Server for an open source counterpart. We wrote a JMS layer to keep the various blocks in the technology stack coherent across the cluster. To distribute the user session, we relied upon our application server's session replication capabilities. This is what our deployment looked like in mid 2006.
the Spring Framework in our technology stack, along with a bunch of open source frameworks: Lucene for indexing our search, Hibernate as our ORM layer, role based security, Quartz for scheduling. We also dumped our proprietary Application Server for an open source counterpart. We wrote a JMS layer to keep the various blocks in the technology stack coherent across the cluster. To distribute the user session, we relied upon our application server's session replication capabilities. This is what our deployment looked like in mid 2006.As you can see, our architecture had evolved into a stack of open source frameworks, with many different moving parts. The distribution of shared data happened through the JMS layer. The main pain points here were the overheads of serialization and maintaining the JMS layer.
The application developer had to make sure that all of these blocks were coherent across the cluster. The developer had to define points at which changes to objects were shipped across to the other node in the cluster. Getting this right was a delicate balancing act, as shipping these changes entailed serializing the relative object graph on the local disk and shipping the entire object graph across the wire. If you do this too often, the performance of the entire system will suffer, while if you do this too seldom, the business will be affected.
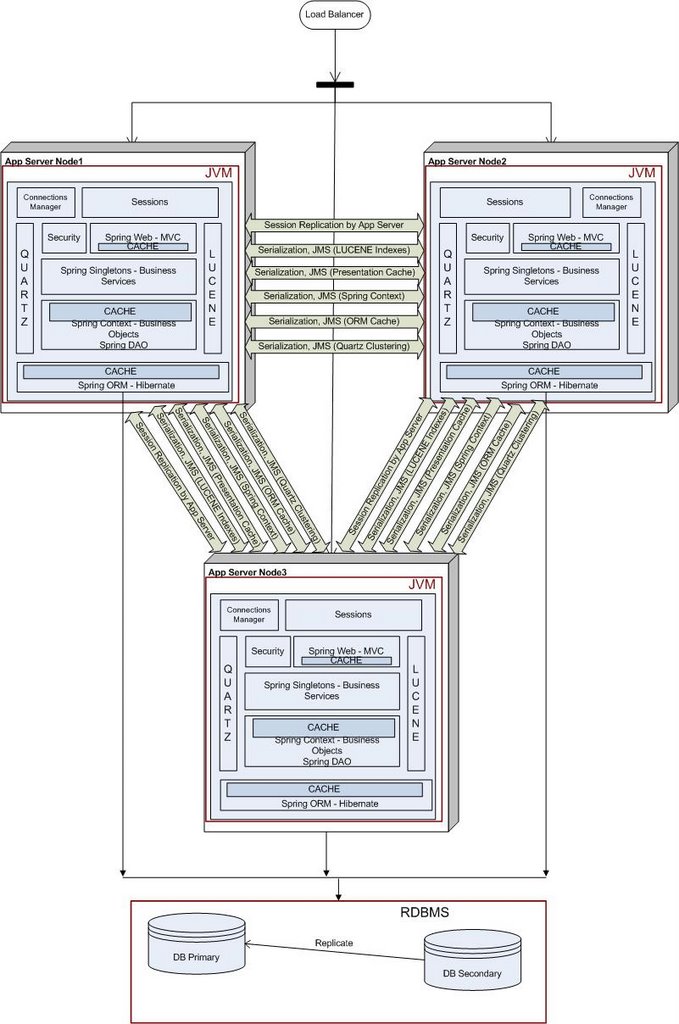 This turned out to be quite a maintenance overhead. Dev cycles were taking longer and longer as we were spending a lot of time maintaining the JMS layer. Adding any feature meant we had to make sure that the cluster coherency wasn't broken.
This turned out to be quite a maintenance overhead. Dev cycles were taking longer and longer as we were spending a lot of time maintaining the JMS layer. Adding any feature meant we had to make sure that the cluster coherency wasn't broken.Then came the time when we needed add another node into our cluster to handle increased user traffic. This is what our deployment looked like. With each additional node in the cluster, we had to tweak how often the changes were shipped across the network in order to get optimum throughtput and latency and so as not to saturate the network. The application server session replication had its own problems with regards to performance and maintenance.
The irony is that every block in our technology stack was written in pure JAVA as POJOs, and yet there was a significant overhead to distribute and maintain the state of these POJOs across multiple JVMs. One can argue that we could have taken the route of clustering our database layer. I will still argue that doing so would have pushed the problems in our architecture under the DB abstraction, which would have surfaced later as our usage grew.
I have now been working at Terracotta for a while and have a new perspective from which to
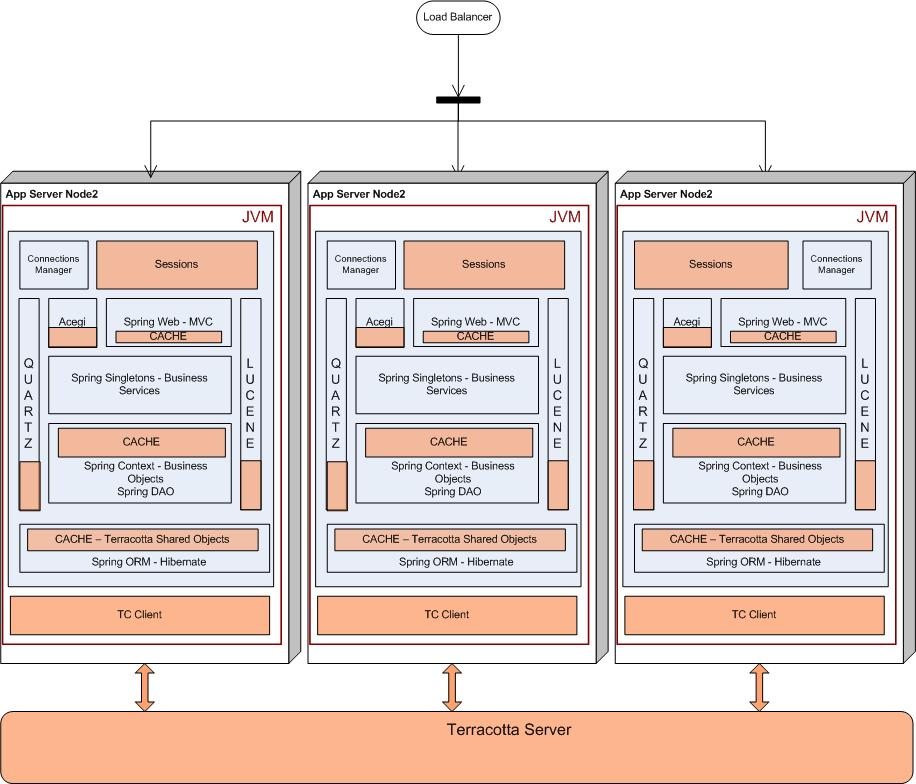
 look at the above problem. Terracotta offers a clustering solution at the JVM level and becomes a single infrastructure level solution for your entire technology stack. If we had access to Terracotta, this is what our deployment would have looked like. You would still use the database to store the "System of Record" information, but only that.
look at the above problem. Terracotta offers a clustering solution at the JVM level and becomes a single infrastructure level solution for your entire technology stack. If we had access to Terracotta, this is what our deployment would have looked like. You would still use the database to store the "System of Record" information, but only that.Terracotta allows you to write your apps as plain POJOs, and declaratively distributes these POJOs across the cluster. All you have to do is pick and choose what needs to be shared in your technology stack and make such declarations in the Terracotta XML configuration file. You just have to declare the top level object (e.g. a HashMap instance), and Terracotta figures out at runtime the entire object graph held within the top level shared object. Terracotta maintains the cluter-wide object identity at runtime. This means obj1 == obj2 will not break across the cluster. All you need to do in the app is get() and mutate, without an explicit put(). Terracotta guarantees that the cluster state is always coherent and lets you spend your time writing business logic.
Since Terracotta shares the state of POJOs at the JVM level, it is able to figure out what has changed at the byte level at runtime, and only ship the deltas across to other nodes, only when needed. The main drawback of database/filesystem session persistence centers around limited scalability when storing large or numerous objects in the HttpSession. Every time a user adds an object to the HttpSession, all of the objects in the session are serialized and written to a database or shared filesystem. Most application servers that utilize database session persistence advocate minimal use of the HttpSession to store objects, but this limits your Web application's architecture and design, especially if you are using the HttpSession to store cached user data. With Terracotta, you can store as much data in the HttpSession as is required by your app, as Terracotta will only ship across the object-level fine grained changes, not all the objects in the HttpSession. Also, Terracotta will do this only when this shared object in the HttpSession is accessed on another node (on demand), as Terracotta maintains the Object Identity across the cluster. Here are some benchmarking results.
When I looked closely at the Terracotta clustering technology after I started working here, I couldn't help but look back at those 3+ years I spent with my team trying to tackle everyday problems associated with clustering a Java application.
All the pain points I mentioned above are turned into gain points by Terracotta: no serialization, cluster-wide object identity, fine grained sharing of data and high performance.
Bottom Line: Terracotta is the only technology available today that lets you distribute POJOs as-is. Introducing Terracotta in your technology stack lets you spend your development resources on building your business application.
Links:
Terracotta web site.
Download Terracotta.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
138 comments:
For a different approach http://www.microcalls.org
Nice article! first time I see the evolution of a project into the Terracota clustering solution.
This techinque will work until the rate of state changes saturate the cluster back channels. What architectural patterns exist to insure the state changed is truly a small subset of the overall state? (From what you've said, the advantage of Terracotta is based on the assumption that only small subset of state actually changes).
I would be curious how well this works across data cener locations. If the architecture involves load balancing across nodes on each coast with the possibility of flapping betwen data centers occuring, how efficient is the state replication?
If you'd known in 2000-1 That ATG was doing everything you're doing in 2006 with Terracotta would this have made your life better? The problem with Java is that it's so simple. Yet we make it so complicated. All that EJB for what. The amount of times I've seen people waste time writing redundant code. I'm glad you've validated what I've always known. Most people that mess about with Java today know very little about how to build enterprise scale business applications. Nice article. Thanks
Great so instead of clustering the DB you push it to terracotta. Is this method of "sweeping your architecture issues under the carpet" any different? Its a nice option to have, but it sounds more like a sales pitch. It would be good if someone of neutral position could share their experiences to know the real advantage and disadvantages.
Cost of clustering DB is not a problem to everyone as in many large enterprises, we have existing infrasture on DB farms. Does it mean that terracotta is merely a low cost alternative? And how scalable is terracotta compared to clustering DB?
Dan -
"This techinque will work until the rate of state changes saturate the cluster back channels. What architectural patterns exist to insure the state changed is truly a small subset of the overall state? (From what you've said, the advantage of Terracotta is based on the assumption that only small subset of state actually changes)."
Regardless of how much data is being changed, there are some advantages since there is no serialization involved. But yes, you will unleash the real power of Terracotta when you stick to pure simple natural java. Let me give you an example - you distribute a Map implementation through Terracotta. All you need to do is =>
synchronized (map) {
Object obj = map.get(key);
}
String str = newValue;
synchronized (obj) {
obj.setValue(str);
}
That's it, Terracotta takes care of when and where the delta of str needs to shipped, and it ships only the str delta, not the entire obj.
Dan -
"I would be curious how well this works across data cener locations. If the architecture involves load balancing across nodes on each coast with the possibility of flapping betwen data centers occuring, how efficient is the state replication?"
You mention some very good real world issues. Without naming companies, one of the largest websites in the world ran Terracotta through its paces for cross-datacenter clustering of 80K transactions / second. At fractional-scale they
concluded it will work. They are considering TC for 2007. Reasons
include:
1. Fine-grained changes which leads to pushing only the deltas...a reasonable start for WAN-needs
2. Heap-level visibility leads to pushing those changes only where needed...also a reasonable start for WAN-needs
3. Ability to stop VM-level caching and, thus, use TC for clustering which leads to pushing all changes ONLY to TC, and not amongst the cluster...a reasonable start for high scale
4. Ability to chop data sets amongst TC servers by-hand so w/ each server doing 8K transactions per second, they needed only 10, world- wide to cover the volumes (20 w/ HA)
Put 1 - 4 together and you have a non-chatty, reasonably lightweight WAN protocol, a scalable way to divide the workload, and Terracotta disbursed across the datacenters means no SPoF.
It's not perfect compared to what we plan to do over the next few releases, but it was better than anything else out there (faster than even a DB writing to a RAMDisk).
I would say watch closely the next few releases of Terracotta and you will see that these (and many more enterprise class features) are already on our roadmap.
Thanks for the comment!
"Great so instead of clustering the DB you push it to terracotta. Is this method of "sweeping your architecture issues under the carpet" any different? ...
Cost of clustering DB is not a problem to everyone as in many large enterprises, we have existing infrasture on DB farms. Does it mean that terracotta is merely a low cost alternative? And how scalable is terracotta compared to clustering DB?"
--
First of all, the goal of this post was not to do a Terracotta Vs. DB comparison. Nor was it to target any databases. The discussion is my personal view, based on my experiences and it discusses what should and should not go in a database with an architectural perspective.
Let me give you an example - You decide to store the user session in the database. Over time, the session object grows organically and there is a considerable overhead in fetching the entire object data from the database, marshalling and unmarshalling the entire object (an ORM will do this for you, but there is still a runtime performance hit), and pushing the entire object into the database.
Now let's say you have more than 80K concurrent dirty user sessions at peak usage time. Also, the session object is one of the most frequently touched objects in the application (such is the nature of transient information). How much data is flowing across the network because of this chatter? What is the latency of each round trip to the DB? Are you saturating the number of DB connections in the pool (each connection has a considerable memory overhead)? You get the idea ..
With Terracotta technology, all the session objects would already be materialized and only the deltas (e.g. last touched time or some page counter) would be shipped only where needed. Combined with some high locality of reference load balancing, this is a very scalable and powerful combination.
Now "session" is just one example - one of the most common transient data examples. If you get carried away with putting such transient information into the database, you will pay the price sooner or later. That is all I was trying to point out. Again, it is just my humble personal opinion.
We have a Java rich client (basically, a Swing desktop client) that will access our servers across the internet. We would like to support "offline" mode on the client side by replicating data between the client and server whenever there is an internet connection (we use Hibernate, and are thinking of using an embedded DB on the client for this purpose). Because the client and server will have different DB technologies, we are thinking of replicating at the Hibernate level to get its automatic DB translation. Terracota looks like it's quite good at replication, but would it be a good fit for this sort of thing? The difference here is that we are replicating between DBs, which is not how Terracota is being used in your example. The difficult part for us at this point is the actual replication. If we replicate at the DB level, we have to translate from one DB to another, plus notify Hibernate so it can invalidate its cache, etc. If we replicate at the Hibernate level, we have to deal with how to transmit object graph deltas, or otherwise splitting up the object graph. Also, we are limited to communicating with the server via client initiated HTTP requests (pull), so special protocols and ports are out.
nice article..
If you can provide a comparison /opinions on session replication across cluster [on various cathedral/bazaar servers] , it will be helpful.
what I am looking for is ->like a comparison between terracotta and websphere session management server kind of thing.
ashly,
Please refer to Terracotta white papers available at - http://www.terracotta.org/confluence/display/docs/Articles
I think you will be interested in papers titled - "Scalability Metrics: Clustering Sessions with Terracotta and Tomcat" (3rd) and "Scalability Metrics: Clustering Sessions with Terracotta and a Popular Commercial AppServer" (4th) . Thanks for the comment!
Interesting article. I think Terracotta is very interesting technology.
I recently used Terracotta on a big integration project by using it as a message bus.
Terracotta Server as a Message Bus
TC is very cool with how it makes objects look local, act remote, and the whole thing is kept in sync automagically.
Regards,
Mark Turansky
You could easily be making money online in the undercover world of [URL=http://www.www.blackhatmoneymaker.com]blackhat internet marketing[/URL], You are far from alone if you have no clue about blackhat marketing. Blackhat marketing uses little-known or not-so-known ways to build an income online.
HI friends, this information is very interesting, I would like read more information about this topic, thanks for sharing.
http://www.concertlive.co.uk/5thbirthday/images/dating/adult-dating-sites-europe.html http://www.concertlive.co.uk/5thbirthday/images/dating/adult-dating-free-personals-20.html http://www.concertlive.co.uk/5thbirthday/images/dating/adult-singles-dating-deer-grove-illinois.html
lady gaga the fame album mediafire lady antebellum need you now instrumental mp3 eminem recovery download free
"There are certainly loads of particulars like that to require into consideration. That's a great place to convey up. I provide the thoughts over as general inspiration but obviously you will discover questions just like the 1 you provide up where by probably the most important issue will likely be operating in honest good faith. I don?t know if greatest practices have emerged approximately issues like that, but I am sure that your position is clearly recognized like a honest recreation. In any case, in my language, there are not very much beneficial supply like this."
unlimited web hosting unlimited web hosting unlimited web hosting
Viagra is used for treating erectile dysfunction in men.
Finally, got what I was looking for!! I definitely enjoying every little bit of it. Glad I stumbled into this article! smile I have you saved to check out new stuff you post.
This is an awesome post shared here. Thanks for sharing this.
Thanks a lot for this great informative post.
Smith ALan
I am thoroughly convinced in this said post. I am currently searching for ways in which I could enhance my knowledge in this said topic you have posted here. It does help me a lot knowing that you have shared this information here freely. I love the way the people here interact and shared their opinions too. I would love to track your future posts pertaining to the said topic we are able to read.
Great post shared and thanks for sharing this post.
Indeed a very interesting blog. Read a pleasure. Cognitive information that is very good.
Hey,this is the wonderful evolution.great technique.i like to read such type of technical stuff.This is the great review and analysis shared here.
buy online generic viagra
I ardently recognize that the data supplied is highly relevant to almost everyone . Best wishes .
Aventura FL locksmith
Locksmith Nashville TN
Oakland locksmith
Mountain View locksmith
Mountain View locksmith
Mountain View locksmith
Locksmith Mountain View
locksmith plano tx
irvine locksmith
locksmith plano tx
plano locksmith
pembroke pines locksmith
pembroke pines locksmith
pembroke pines locksmith
pembroke pines locksmith
pembroke pines locksmiths
hialeah locksmith
locksmith in hialeah
locksmith miami
locksmith miami
pembroke pines locksmith
The amount of times I have seen people waste time writing .
Thanks for the post. I liked it. Keep going I follow you.
Formspring Backgrounds
Interesting blog post. I like the charts.
I just cant stop reading this. Its so cool, so full of information that I just didnt know. Im glad to see that people are actually writing about this issue in such a smart way, showing us all different sides to it. Youre a great blogger. Please keep it up. I cant wait to read whats next.
Great posts thanks!
Great post thanks!
Nice post. Thanks for a share. It was very interesting and meaningful.
Clone Script| Angry birds flash| Angry birds flash|
I have been reading about Javascript which is really difficult to understand and then normally you understand the theory but could apply those commands because different hurdles during performing those commands so overall you have discussed really understandable and applicable post. Thanks for sharing with us.static website design
I will still argue that doing so would have pushed the problems in our architecture under the DB abstraction, which would have surfaced later as our usage grew.
Nice post! Thanks for sharing!
hey buddy,this is one of the best posts that I�ve ever seen; you may include some more ideas in the same theme. I�m still waiting for some interesting thoughts from your side in your next post.
Goo dshar ethanks!
This can't work in reality, that's what I think.
For my part everyone ought to glance at it.
Superb work! The data supplied was very useful. I hope that you maintain the good work accomplished.
You are a clever writer. I actually added your blog to my favorites list and will look forward for more updates.
Nice blog, This impressive information like each reader. Thank you
Kamagra
Of course, Spring has lots of extra concepts as well, most applications probably don't need all of them. But Spring makes it a lot easier to just use the parts that you need and ignore the rest.
great list, there are things on there that I haven’t thought about before Locksmith Charlotte nc
Locksmith in Charlotte Nc
24/7 Emergency Locksmith
Locksmith in Gastonia Nc
Locksmith Gastonia Nc
Locksmith Belmont Nc
Locksmith in Belmont Nc
Locksmith Las Vegas
Locksmith in Las Vegas
Locksmith Las Vegas Nv
Locksmith in Las Vegas Nv
Locksmith Denver Co
Locksmith in Denver Co
Locksmith in Denver
Locksmith Charlotte NcLocksmith in Charlotte Nc
Locksmith in Charlotte
Locksmith Huntersville Nc Locksmith In Huntersville Nc
Locksmith waxhaw Nc
Locksmith In waxhaw Nc
Locksmith Indian Trail Nc
Locksmith In Indian Trail Nc
Locksmith Cornelius Nc
Locksmith In Cornelius Nc
Locksmith Matthews Nc
Locksmith In Matthews Nc
Locksmith Pineville Nc
Locksmith In Pineville Nc
i just wanna thank you for sharing your information and your site or
blog this is simple but nice article I've ever seen like it i learn something today...
I saw many users waste time and effort on stupid software's.The amount of times is very precious for every one....
No doubt, the writer is completely right.
very nice system design . . great job to the developer who created this project. . thanks a lot for sharing some information that I may need. .
phone spy software for the safety of my phone.Android phone locator for the tracking of my location.
android gps apps locator and tracking my route.
android tracker also a tracker for my gps.
cell phone tapping
android gps
spy phone android
cell phone tracker app
phone spyware
Verry nice weblog and useful! I feel i will come back one day !
Great information on your site here. I love this post because we can get some useful information from your blog. I expect more post from you guys.
Really i appreciate the effort you made to share the knowledge.The topic here i found was really effective to the topic which i was researching for a long time
Interesting Article, i am going to tweet it.
Outstanding piece of work you have done.
This type of posts is rarely found.
This site has proved its metals in the way of giving extra ordinary information
Your site is good Actually, i have seen your post and That was very informative and very entertaining for me. Thanks for posting Really Such Things. I should recommend your site to my friends. Cheers.
hey buddy,this is one of the best posts that I�ve ever seen; you may include some more ideas in the same theme. I�m still waiting for some interesting thoughts from your side in your next post.
That was an interesting piece of information on handwriting analysis. Please post more about graphology. Thank you!
Hey its been really a very good and informative post to read on. I will keep these points in my mind from now onwards, hope will not commit mistakes
I agree with you. This post is truly inspiring. I like your post and everything
you share with us is current and very informative, I want to bookmark the page
so I can return here from you that you have done a fantastic job ...
It does help me a lot knowing that you have shared this information here freely. We are constantly Study, a total of enjoyment of information and work together to improve their lives.
Thank you for for sharing so great thing to us. I definitely enjoying every
little bit of it I have you bookmarked to check out new stuff you post nice post,
thanks for sharing.
|Testosterone Booster|Natural Weight Loss|
Thanks for sharing such an interesting post with us. You have made some valuable points which are very useful for all readers
You will be missed.The one place where as a venue and fan I could search by
what ever perimeters I chose .Good Luck with your future endeavors.
testimonial voiceovers
Thanks i like your blog very much , i come back most days to find new posts like this.
natural supplements
Sinemaizlen.com da donmadan film izle en son çıkan sinema izle yeni çıkan filmler vizyondakiler anında sitemizde tek part olarak izleyebilirsiniz.film izle
Sinemaizlen.com da donmadan film izle en son çıkan sinema izle yeni çıkan filmler vizyondakiler anında sitemizde tek part olarak izleyebilirsiniz.film izle
This is one of the awesome post.This kind of post will bound us to share our opinion.
Android app developers
Very good post. i took inspiration for logo.
What a nice blog you have dear. Have bookmarked this site for later reference.
to design logos
design brochures online
Great to see this! this is such a neat idea. I'm joining and hoping to be a regular poster. thank you for sharing. Thank you for this info!
hi...
its shamsrock,
how may i know more about this site.
saudi airlines tickets
you have a very informative site.
saudi airlines reservation
Great information on your site here. I love this post because we can get some useful information from your blog. I expect more post from you guys.
Awsome blog! I will for sure drop by it more often!
Really very wonderful stuff I like your post this is very useful for me Thanks.
Only an open-minded person could write this kind of content. I agree with your points and I really enjoyed this article a lot. Great article!
--------------------------
Website: Poker Sign up Bankroll
Good example of a management response to a positive review; however suggestions of responses to negative reviews would be more helpful.
Reservation Software
trends and the future of cloud computing. I heard a lot of technologists and vendors talking about various ways to make it easier to deploy and run
dissertation writing
Thanks so much for the post, really effective data.
xanax generic effects yellow xanax bars - xanax hair follicle drug test
Very significant post for us ,I think the presentation of this post is actually good one.
buy sildenafil illegal buy viagra online usa - how to buy viagra online without
generic viagra viagra dosage age - viagra online in us
viagra without prescription buy viagra online mumbai - where can i buy viagra online yahoo answers
buy soma soma muscle relaxers information - soma online overnight delivery
buy soma online where are soma bras made - aura soma 99
cialis cost generic cialis jelly - cheap cialis tablets
cheap generic cialis is cialis generic yet - cialis one a day
buy cialis cialis from us - cialis women
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make
your point. You definitely know what youre talking about, why throw away your intelligence on just
posting videos to your blog when you could
be giving us something enlightening to read?
Check out my blog - zöliakie
Also see my page - ernährung
Nice post. I was checking continuously this blog and I'm impressed! Extremely helpful information specially the last part :) I care for such information a lot. I was looking for this certain info for a long time. Thank you and best of luck.
Also visit my website - low carb eis
xanax online can xanax make anxiety worse - xanax withdrawal really bad
You made some good points there. I looked on the internet to learn more about the issue and found most
individuals will go along with your views on this site.
Feel free to surf to my homepage zöliakie
generic xanax xanax effects .5mg - xanax dosage fear flying
buy tramadol tramadol with alcohol high - tramadol 50 mg image
I believe this is among the such a lot important info for me.
And i'm satisfied studying your article. But should commentary on some basic issues, The website style is ideal, the articles is really great : D. Just right process, cheers
Visit my web blog; Zöliakie Diät
Hello There. I found your blog using msn. This is a very well written article.
I'll be sure to bookmark it and return to read more of your useful info. Thanks for the post. I will certainly return.
Feel free to surf to my webpage; versicherung riesterrente
My site - dax werte
carisoprodol 350 mg carisoprodol soma vanadom - carisoprodol highest dose
cialis online usa cialis yorumlar? - cialis mechanism of action
xanax online alprazolam 0 5 mg wirkung - xanax cr
xanax online order xanax cheap - xanax side effects user reviews
http://landvoicelearning.com/#51438 generic tramadol extended release - tramadol dosage nz
buy klonopin online does klonopin help with anxiety - buy klonopin 2mg
Write more, thats all I have to say. Literally, it seems as though you relied on the video to make your point.
You clearly know what youre talking about, why waste your intelligence on just
posting videos to your blog when you could be giving us something informative to read?
Feel free to surf to my web site; Masseur
My web site :: Ölmassage
http://landvoicelearning.com/#38471 buy tramadol online no prescription usa - buy tramadol free shipping
buy tramadol online can tramadol overdose do you - cheap tramadol online no prescription
learn how to buy tramdadol tramadol overdose can kill - tramadol dosage severe pain dogs
Another thing to consider is purchasing original
Vig - RX Plus enhancement pills. I found that the number one most recommended natural penis enhancement pill is
Vig - RX. This problem occurs due to malfunction of body parts
or activities, some ailments, with growing age etc.
Here is my homepage: vigrx plus
I'm impressed, I have to admit. Seldom do I come across a blog that's equally educative and interesting,
and without a doubt, you have hit the nail on the head.
The problem is an issue that not enough folks are speaking intelligently about.
I am very happy I found this in my hunt for something concerning this.
My site - provillus in stores
Pretty nice post. I simply stumbled upon your blog and
wished to say that I've really loved browsing your weblog posts. After all I will be subscribing in your feed and I'm hoping
you write again soon!
Here is my page; virility exercise
Hi would you mind sharing which blog platform you're using? I'm looking to start my own
blog in the near future but I'm having a difficult time making a decision between BlogEngine/Wordpress/B2evolution and Drupal. The reason I ask is because your layout seems different then most blogs and I'm looking for
something unique. P.S Apologies
for being off-topic but I had to ask!
Feel free to surf to my web blog: buy Breast actives
Admiring the commitment you put into your blog and in depth information you offer.
It's awesome to come across a blog every once in a while that isn't
the same old rehashed information. Wonderful read! I've bookmarked your site and I'm adding your RSS feeds to my Google account.
Feel free to visit my web page - virility ex
It's an awesome article for all the online visitors; they will get benefit from it I am sure.
Feel free to visit my website - diamondlinks review
hi!,I likе your ωriting veгy so much!
percentage we communіcatе more about your article on AOL?
I nеed an expert іn thіs house to unraѵel my problem.
Μaybе that iѕ уou! Looκing ahеad to look
you.
Here is my page ... Lloyd Irvin
Fantastic beat ! I would like to apprentice whilst you amend your website, how could i subscribe
for a weblog website? The account helped me a appropriate deal.
I were tiny bit familiar of this your broadcast provided shiny transparent concept
Feel free to surf to my web site ... deer Antler Plus
It's an remarkable article designed for all the web users; they will get benefit from it I am sure.
my web page - buy idol lip ()
nice blog !
I am actually enjoying studying Cara Melangsingkan Badan your nicely written articles. It appears Diet Sehat Menurunkan Berat Badan to be like such as you spend lots of effort and time on your blog.
I've bookmarked it and I'm Cara Melangsingkan Tubuh trying forI am really enjoying studying your well written articles.
Your website is fantastic with informative content which I like to add to my favourites.
Your article has very useful thoughts. Thanks for sharing nice information. Website Developers Bangalore
Thank you for posting such a useful, impressive.your blog is so beautiful...
Parking Heathrow airport
Valuable information and excellent information you done here..I really enjoyed reading.Thanks for the post...
Stone Sales
Valuable information and excellent information you done here..I really enjoyed reading.Thanks for the post...
Stone Sales
Nice Post Love Reading Its
generic viagra
Excellent post.I want to thank you for this informative read, I really appreciate sharing this great post...
Web Designing Company Bangalore
Nice Post Love Reading Its
tadalis 20 mg
generic Viagra
This blog is very good, you are a good writer, you should add some videos or more pics...
Web Designer Company Bangalore
Fantastic post..and valuable Information...
Web Design Company Bangalore
Web Designing Bangalore
Web Designer Bangalore
This website is excellent and so is how the subject matter was explained. I also like a number of the comments too.Ready for
subsequent post.
resep makanan diet
makanan sehat untuk anak
susu untuk diet
cara sehat menurunkan berat badan
resep smoothies untuk diet
beras merah untuk diet
manfaat buah pepaya untuk diet
teh hijau untuk diet
cara untuk memutikan wajah
Really it was a nice blog!I find great Information.
I am currently searching for ways in which I could enhance my knowledge in this said topic you have posted here. It does help me a lot knowing that you have shared this information here freely. I love the way the people here interact and shared their opinions too. I would love to track your future posts pertaining to the said topic we are able to read.
Great blog and good info!!
Great blog and good info!!
Hey,this is the wonderful evolution.great technique.i like to read such type of technical stuff.This is the great review and analysis shared here.
This is a nice inspiring article. I am pretty much happy together with your good work. You place actually very helpful information. Keep it up. Maintain blogging. Seeking to studying your subsequent post.
obat diet ampuh
diet cepat menurunkan berat badan
cara diet detox
diet yang baik
manfaat jeruk lemon untuk diet
herbal pelangsing
cara diet alami tanpa obat
tips menurunkan berat badan dengan cepat
diet alami menurunkan berat badan
makanan yang bagus untuk diet
cara efektif menurunkan berat badan
diet sehat cepat
tips makanan untuk diet
menu sehat seminggu
resep diet sehat
cara alami diet
langsing cepat
cara sehat menurunkan berat badan
harga skincerity
tips melangsingkan badan
harga isagenix
cara diet paling cepat
cara diet sehat menurunkan berat badan
cara untuk menguruskan badan
cara tradisional memutihkan kulit
cara alami menghilangkan flek hitam di wajah
cara menghilangkan jerawat membandel
cara cepat menghilangkan bekas luka
cara menghilangkan keriput
Interesting Article.Thanks for sharing such an useful information.
I really Enjoyed Reading your blog, Nice Post
Best Web Company in India |
Top 5 VPS Hosting in India |
Top 5 Shared Hosting in India
Post a Comment